
Dr Ramon Brasser is a planetary scientist currently working at the Konkoly Observatory in Budapest, Hungary. His research revolves around the formation and evolution of the planets in the solar system and beyond. He takes an interdisciplinary approach to understanding the ability of different planets to host a biosphere. Biospheres are the thin layer of crust and atmosphere that supports life here on planets like Earth. He also studies the physical impact of asteroids or comets have on planets. Modelling planet formation on HPC technologies can provide a better understanding of the planetary conditions needed to support life.
In October 2024, Dr Brasser won the Best EuroHPC User Award at the EuroHPC User Day in Amsterdam. In this interview, Dr Brasser discusses sustainability, respectful behaviour and how to drive efficiency when accessing the EuroHPC infrastructure and resources.
Can you explain your approach to ensuring efficient use of the EuroHPC JU public supercomputer infrastructure?
Yes, here are a few tips for researchers to consider when applying for EuroHPC time. It could save you a lot of time and a lot of resources:
- Learn about the different EuroHPC Systems: When you submit a proposal for a project, EuroHPC JU will tell you how many CPU or GPU hours are available on each HPC system. This will help you to select which HPC system you are going to submit a proposal to. It is important to understand what the available systems can do, and you can identify which one best fits your project. It’s not always about going for the newest system.
- Do you really need all that speed? While some of the newer systems like MareNostum 5 or LUMI might be faster, they could exceed the requirements for your planned research.
- Test first! EuroHPC JU recommends that you first test their software on a system, before applying for more core hours. Since several systems have the same hardware, it doesn't matter which system you test it on. If users test their software in advance, EuroHPC JU evaluation panels can be sure the software is well-optimised to make efficient use of the hardware.
- Ask for help: The team at EPICURE, a project funded by EuroHPC JU to improve user support, will help you optimise your software. This is extremely useful because you can test your software and see how it scales before you submit a full proposal. For example, we have one code for planet formation which is CPU based and that is not so well optimised. It works but could be faster, though achieving that would take a lot of time and effort. EPICURE could us to optimise our code before applying to run it on one of EuroHPC JU supercomputers.
What is your advice to new users of EuroHPC JU systems?
As a new user, I would hesitate to directly request extreme scale access to the EuroHPC JU infrastructure in the first instance. There is a risk that the evaluation panel might say that the project is not using the hardware optimally which would lead to a waste of resources (and is very costly in terms of time and energy usage).
It is worth taking the time to pre-screen the system that you want to use. I would start by applying for a benchmark for development call to test your project and ask for assistance from EPICURE to optimise the software. When it is ready, I would then apply to run it on one of EuroHPC JU supercomputers.

Your knowledge and application of energy conservation strategies for HPC was another element of your selection as an awardee. What should users be aware of in relation to sustainable HPC usage?
This is an issue of growing concern in the HPC community. My former Master’s supervisor, Dr Simon Portegies Zwart, published an article in Nature Astronomy (2020) entitled “The ecological impact of high-performance computing in astrophysics”. The article points to two ways astronomers can significantly reduce their carbon footprint. First, when possible, they should run their codes on GPUs. If the development of GPU code is not possible, they should run the code on multiple CPU cores instead of just one. Secondly, Dr. Portegies Zwart advises researchers aiming for greater sustainability to reduce their reliance on Python, a popular and easy-to-learn programming language. Instead, he recommends using high-performance libraries or switching to more efficient programming languages such as Alice, Julia, Rust, or Swift. But ideally codes should be written in energy-efficient programming languages such as C/C++ or Fortran. The article showed that these two changes can significantly improve the environmental impact of HPC projects. (See Figure 1)
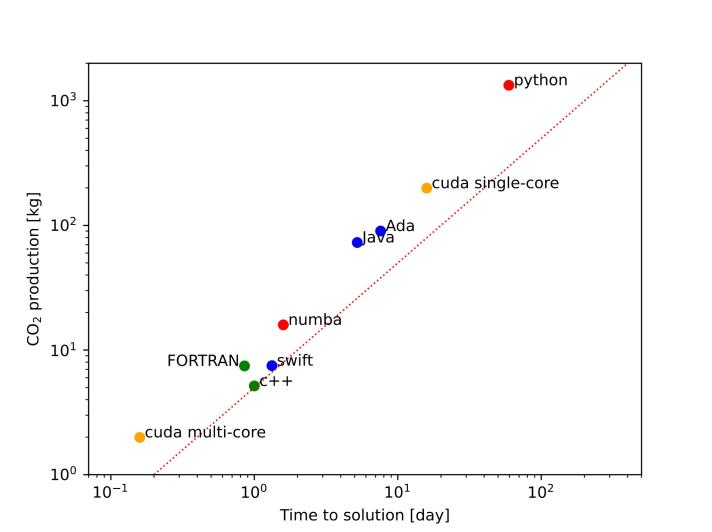
From my crude understanding Python is slow when it comes to arithmetic, although with NumPy this can be improved, but it is never as good as C++ or FORTRAN.
So one thing I feel is important is that if you are doing numerical work and you are using GPUs then it needs to be in a language like C++ or FORTRAN or CUDA.
Another thing I consciously try to do is advanced testing and I try to scale the code properly with the number of CPU cores, but that only works up to a certain limit.
For example, I can use 4 cores to run more simulations on a single machine until all cores are occupied—the scheduler handles this automatically. As the number of particles decreases, I no longer need 4 cores; just 2 or 1 will suffice. I can adjust my script to switch from 4 cores to 2, and then from 2 to 1, ensuring I am not wasting resources. (See Fig 2)
Overall, I think it might be helpful if more consistent information was available on energy consumption from across the European supercomputer infrastructure so users can generate accurate estimates of their energy consumption for their final reports. It is good for users to be aware that the data required for this varies from supercomputer to supercomputer (even in different months of the year on the same system).

You were also nominated for the Best EuroHPC User Award for respectful behaviour on the system concerning other users. How can researchers and others working on the EuroHPC systems replicate this approach?
Like any shared space, be a good citizen and clean up after yourself! I backed up my data frequently, usually once a week, so it can be cleared from the machines and is not sitting there. I have heard complaints in the past of some users not downloading their data from the system despite multiple requests to do so. I think this is a good thing to be conscious of and to do often. The moment the project is done, I remove the files and let people know so they can deactivate my account and remove files from their system. Good communication goes a long way, it is helpful to let staff know how you are doing so they can plan based on that information also. That’s about building a relationship of trust and being aware of the demands on the staff and system. It becomes a reciprocal relationship that allows you to get the right support when you need it also.
Another thing is to frequently monitor your simulations. I do this once every 24 to 48 hours. If one or several have stopped and did not restart, I must check that manually because sometimes there is an error, and the script gets stuck in an infinite loop hogging the scheduler, or in other cases it just won’t start. Since the clock is ticking down from the moment access is granted, I do my best to use every minute and not have time wasted because some simulations ended up misbehaving.
Finally, could you tell us about your effective use of the GPU partition in your research which was judged as demonstrating optimal resource allocation.
The software that I use for the GPUs was not written by me, but I have been involved in its development over the last six years through a colleague, Simon L. Grimm, who is the author. He invited me to be a co-author of the second paper regarding this software in 2022 precisely because I have been one of the primary users; it allows us to go above and beyond what I can do with CPU-based codes.
To give you an example, if I use one single CPU, I can run planet formation simulations with 2000 bodies, which are not all fully interacting. It takes about two months to run this kind of simulation. On the GPUs it also takes two months, but I can go to tens of thousands of bodies which are fully interacting. And for simulations that attempt to form a small planet like Mars or Mercury, this high number of bodies is absolutely necessary.
Even now we are running into the limitations of the hardware, so we need to work with software solutions. Our aim is to make the code faster by having multiple regions where the time step that you take is different, and we can make an approximation to the force which allows us to use millions of particles on one card. Optimising GPU and CPU use is the future, because then we can really focus on forming small planets like Mars and Mercury. But this kind of research requires certain approximations to be made, and we are already using 80 to 90 percent of the GPU’s capacity, especially when the number of particles is high. When the number decreases you cannot use the GPU optimally so when the number of particles is low enough, we switch to CPU because at that point the CPU is more efficient than the GPU. It's like a hybrid scheme, which is why going forward I will apply for CPU and GPU access within the same proposal. When we get to the millions of particles per GPU card, that's really when it will fly. But we need to test first to see how it scales. When we start with GPU and switch the CPU then you really get the fastest possible speed which means you're using the hardware the best possible way and hopefully being more energy efficient too.
- Publication date
- 30 January 2025
- Author
- European High-Performance Computing Joint Undertaking