Wouldn’t it be amazing if everyone could interact with advanced technology barrier free? Professor Lale Akarun and her research team at Boğaziçi University have been awarded hours by EuroHPC JU on the LUMI supercomputer in Finland for a project that works towards allowing the Deaf community to use sign language to interact with computers in the same way that many of us now do using voice recognition. This research aligns with the European Commission’s goal to create a barrier free way of life in Europe with the Strategy of the Rights of Persons with Disabilities 2021-2030 and initiatives like AccessibleEU and the European accessibility act.
| In this interview, Professor Akarun shares how access to supercomputers has helped move forward her research and discusses the potential for Artificial Intelligence (AI) to make interactions with public services more seamless for the Deaf community. |
Early in your career your research focused on motion analysis, gestures and 3D human facial recognition. Can you tell us about this work, and how it led to your research on sign language?
My research specialises in understanding human behaviours from images, especially detecting and recognising faces, facial expressions, body movements and hand gestures. My Master's thesis, in the 1980s, was on speech recognition. This was the early years of this kind of research, and the technology was not mature enough. I then switched subjects and started working on ‘computer vision’ and again, the technology was not mature enough for the research I wanted to do. At the time, I would tell students that just as speech recognition was starting to become a mature technology, ‘computer vision’ would one day also be part of our lives. Slowly but surely, this became true. ‘Computer vision’ applications began to emerge more recently in areas such as license plate recognition, document processing, biometrics, object recognition, and other human-computer interactions based on vision. I was working on these problems such as detecting different human physical positions, recognising bodily gestures, and interacting with computers using these gestures. |
 |
Why did you focus your research on sign language?
I was always fascinated with sign language. In the early 2000s recognising isolated gestures was of interest to the ‘computer vision’ community and this extended naturally to isolated sign language recognition. Sign language, the language of the Deaf, is a visual language relying on hand shapes, upper body gestures, mouth gestures and facial expressions. Humans evolved to use language earlier with signs, so sign language is older than spoken language. Spoken languages have replaced signing in hearing communities, but we continue to use hand gestures and facial expressions to accompany our speech. For the Deaf, sign language is the primary means of communication. Every Deaf culture has its own sign language independent of the spoken language; for example, there is a British Sign Language and an American Sign Language. This challenge I took on was to carry out research on the different types of sign languages that are used across Europe. We collected sign data and to train models for isolated sign language recognition |
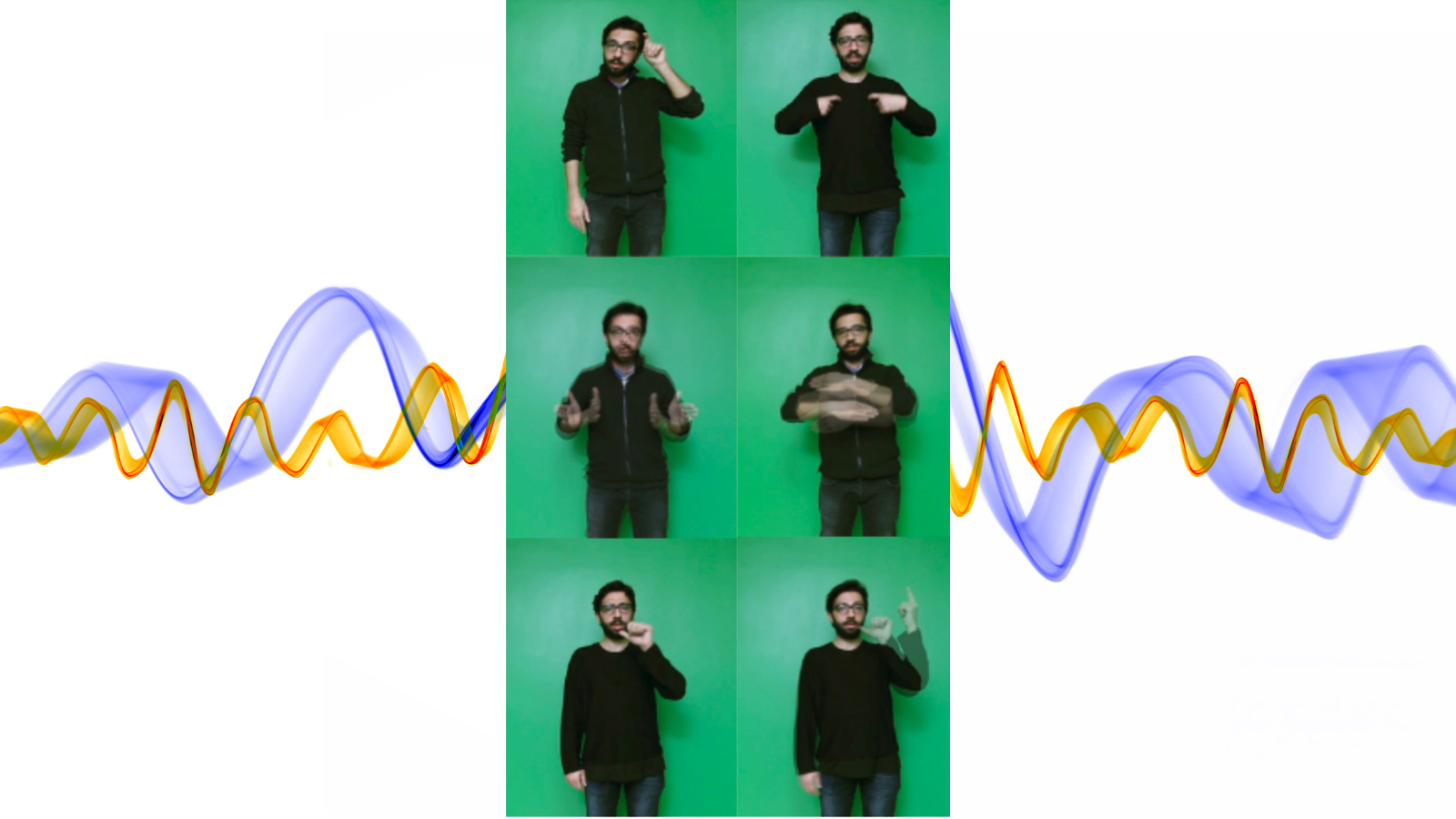 |
How did you approach creating datasets for sign language?
The early datasets we collected were in controlled environments; isolated signs performed several times by professional signers. In these videos, the signer starts with the hand down in a resting pose, performs the sign, and finishes by returning their hands to the rest pose. However, in real life, signers connect signs and perform them much faster. Signs change according to which sign they succeed or precede, the timing, the synchronisation of manual and nonmanual cues, everything adds to the meaning. This necessitates different approaches. Starting about 10 years ago, neural machine translation approaches began to be applied to sign language. This was the era of deep learning, so deep neural networks were used for visual representation as well as translation. You need substantial amounts of data and computational resources to do that. Another thing to take into account is that languages have different lexical sizes. Spoken languages usually have hundreds of thousands of words (with some variation from language to language). Individuals, on the other hand, have smaller vocabularies, in the tens of thousands, because fewer words are sufficient for everyday tasks. Sign languages usually have just a few thousand words. I worked on a previous project to develop sign-based user interfaces for Deaf people in hospitals and banks. We worked out common terms they would need in a bank, like bank account, interest rate, and so on. We quickly realised that signers do not have signs for these concepts, since they rarely used banking services due to communication difficulties. We described the concepts, and they signed them, and it became apparent that they use the same sign for different words. There is a lot of improvisation in sign language. This is one of the factors making sign language dataset collection difficult. One signer improvises but another will say this is not a valid sign. There are also many dialects. This is also an issue in spoken languages, but they usually have larger and better-documented vocabularies. After all, languages are a living entity. They change all the time. New words get invented to describe new concepts and other words get outdated or change meaning. We have to develop technologies that can take these changes into account. A smaller vocabulary size may be seen as an advantage in creating datasets for sign language since you may capture the language with less data. But this is a visual language which creates different challenges - signer pose, camera placement, illumination, the two hands occluding the face, body and each other. These must be dealt with along with the issue of improvisation.
How have EuroHPC’s supercomputers contributed to your research?
In the old days, a desktop computer with a good GPU card was all you needed. In the era of deep learning and large language models, you need more and more computational resources. In the beginning we were aiming to purchase more powerful servers but could not keep up. These machines became outdated after a few years, and it is very difficult and expensive to maintain them. We have used the national TUBITAK ULAKBIM High Performance and Grid Computing Center (TRUBA resources) for our research, but the GPU cluster is shared by the whole country; and the resources are limited. Then we learned of the EuroHPC JU Access Call for AI and Data-Intensive Applications and applied with our project. Access to the EuroHPC infrastructure enables us to carry our research to a different level. Large language models have revolutionised the whole field of machine learning, but they are very costly to train and even fine-tune. With our previous supercomputing resources, training would take weeks or months, and we would exceed our allocated quotas before the models converged. Therefore, before the access now granted to us by EuroHPC, this kind of work would be out of the question.
How will your research benefit the sign language community?
| European public service providers are mandated to employ translators to provide access to all public services for the Deaf community. However, translators are in short supply, and this limits access for Deaf users to services, making them dependent on outside resources. They cannot just walk into any office and get services. They must apply and make advance appointments for everything. If we can achieve perfect translation between sign language and spoken languages, their access to services will be seamless. There is real potential with HPC and AI to deliver that. Our project, “Investigation of Self Supervised Tokenization for LLM Based Sign Language Translation”, will enable translation from Turkish sign language to Turkish text. This is only a short project but once it is finished we will develop user interfaces to enable the Deaf community to use sign language for interactions with computers. |
 |
What are the computational methods that underpin this project?
The translation models we use are based on a machine learning model called T5, which is a transformer-based encoder-decoder architecture. We have used different versions, with differing sizes including one that has been trained in Turkish. We plan to use different sign cue representations as input to the model, some pose based, others image based, including supervised and unsupervised representations. Another technique we plan to use is “discretization” which is a method for converting continuous data into discreet categories. Sign videos are inherently continuous. For example, when you move your hand, the movement is continuous. Discretizing movement may be done in different ways but if you classify movements in categories as up, down, right, left this is quantization to four discrete symbols. We plan to use quantization in the representation space at a much more abstract level to map a large complex set of movements and translate them into a smaller set with a limited number of elements. American Sign Language (ASL) is the most abundant data source so we will start with ASL resources to train models and then use transfer learning to utilise these models in Turkish Sign Language translation.
In the past, we were creating isolated sign language datasets in controlled environments, like visual dictionaries for signs. Now, we would like to collect continuous signing data. This can assist organisations across European to provide access to services for the Deaf community in their native sign language. As public television provides this service, there are many sign-annotated videos on YouTube with text annotations of the speech. This provides a very rich data source. The YouTube ASL dataset has approximately 960 hours of video, from 2800 unique signers, collected in uncontrolled environments. This is annotated with English text and presents an excellent opportunity for training translation models.
Since the beginning of our project, we have also collected a new dataset of Turkish Sign Language, and we have trained an LLM with it. This new dataset also consists of YouTube videos annotated with Turkish sign language (TİD). We have used it to train a Turkish language LLM developed in our department, called TURNA. We are just starting this new phase of the project, but we have already obtained good results. Access to LUMI-G now allows us to accelerate our research and we can’t wait to continue to further develop applications that could be a game-changer for the deaf community
More about Professor Akarun and her team
 |
Lale Akarun is a Professor of Computer Engineering at Boğaziçi University in Istanbul. Her research field is computer vision, a scientific field and branch of Artificial Intelligence (AI) that deals with ways computers can extract meaningful information from digital images or videos. With a specialisation in human biometrics and human-computer interaction, she has led on or participated in more than 30 research projects including 9 international collaborations. She served as Vice President of the International Association for Pattern Recognition from 2018 to 2024, and she currently sits on the Executive Committee of the Science Academy of Turkey. In November 2024, along with her project team (Dr Murat Saraçlar, Dr Inci M. Baytaş, Dr. Kadir Gökgöz) Professor Akarun was awarded computational hours on the LUMI supercomputer in Finland under the EuroHPC JU Access Call for AI and Data-Intensive Applications. The project aims to develop a tool for translating sign language into text of spoken languages. This tool will lead to the development of user interfaces, enabling the Deaf community to use sign language for interactions with computers, ultimately improving their daily lives. |